中文乱码三四五六区 乱码锟斤拷怎么解决
中文乱码三四五六区,随着中文处理技术的不断发展,很多人可能已经忘记了以前常见的中文乱码问题。然而在某些情况下,中文乱码依然会困扰着我们,尤其是在三四五六区这些地方。这些地区可能使用了不同的编码方式或者是由于操作系统或软件的原因,导致中文变成乱码。针对这种情况,我们可以采取一些解决办法,比如更改编码方式、下载安装字体或者尝试使用其他软件。通过这些方法,我们可以方便地解决中文乱码问题,让我们的电脑能够正常显示中文内容。
乱码锟斤拷怎么解决
话说你们有没有经常遇到这种体系的文字,不属于任何一国的文字体系,俗称乱码。这个神秘的乱码是怎么形成的,各位看官听我细细道来。

计算机只明白0和1这两个数字,那我们是如何将数字,字母,汉字,其他国家的语言,甚至是表情包存储在计算机里并将它们显示在屏幕上的呢?这就要用到今天我们今天的主角编码了,ASCII/GB2312/GBK/Unicode/UTF-8等等。
首先我们给出这些编码的发明顺序,以此顺序梳理出编码的由来:ASCII -> GB2312 -> GBK -> GB18030 -> USC(即unicode) -> UTF-8
首先是ASCll编码:计算机最早是由漂亮国发明的,发明计算机的目的就是用来存储和计算的,所以美国人必然会遇到一个问题:怎么存储他们国家需要用到的语言和字符?所以美国人在1967年发布了ASCII编码,ASCII编码表包含了美国人会用到的英文字母、阿拉伯数字(也就是 1234567890)、标点符号(,.!等)、特殊符号(@#$%^&等)以及一些具有控制功能的字符(往往不会显示出来,比如回车、换行等等),美国人将这些字符按照顺序从0代表空字符开始一直到127代表删除结束一一罗列出来,0~127的编号则叫做‘码位’,这些码位转换成二进制便可以被计算机存储了。
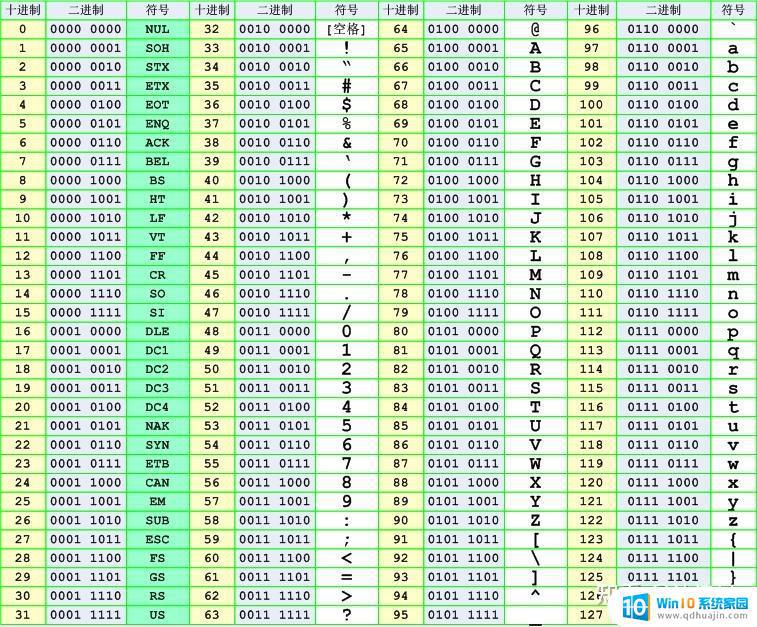
由于计算机是以8位二进制为基本单位进行读写,所以在0~127转换成二进制后,需要凑齐8位,不满8位的在前面补0,以固定的8位长度来存储每个字符。字符与计算机储存的内容一一映射,这种映射的过程叫编码。以上字符与0~127的映射,0~127与计算机储存的8比特二进制存储内容的映射,则叫做ASCll编码。
GB2312编码:但ASCll编码只适用于英文文本,当我们中国人开始使用计算机的时候,ASCll字符完全不够用了,所以有了我们国家自己制定的GB2312编码,于1981年发布。那GB2312编码的字符集是怎么设计的呢?我们国家使用了分区管理的方式,共计94个区,每个区含94个位,共8836个码位。
01-09区收录除汉字外的682个字符;10-15区为空白区,没有使用;16-55区收录3755个一级汉字,按拼音排序。56-87区收录3008个二级汉字,按部首/笔画排序。88-94区为空白区,没有使用。它这个码位是怎么编号的呢?比如看这个'y',在03区第8行第9列,所以0389就作为'y'的码位了。

现在有了码位,那计算机又是怎么根据这些码位来存储的呢?用‘侃’字举例,它的码位是5709,分别将57和09转换成16进制0x39和0x09,0x39和0x09分别加上0xA0变成)0xD9和0xA9,最后将0xD9和0xA9合并,就是'侃'这个字的GB2312编码'0xD90xA9'。
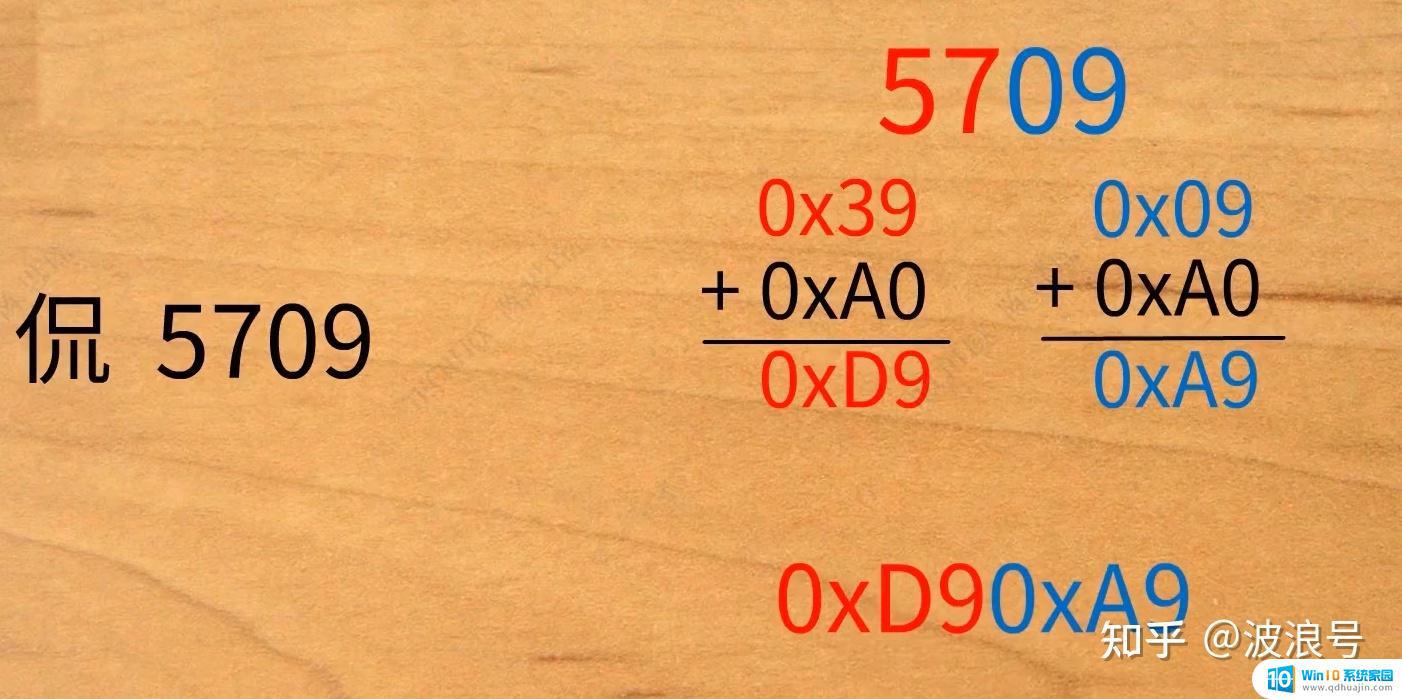
码位转成编码的时候为什么要加上0xA0呢?应该是为了让GB2312向下兼容ASCll编码,ASCll编码只有128位,如果编码小于128,则表示是ASCll码,如果连续碰到两个大于127的8位,就代表可以组合成一个GB2312编码。
GBK由于汉字越来越多,以前GB2312收录的汉字不够用了,需要将以前GB2312中一些没有用上的码位用上,并不再规定低位大于127,只要保证高位大于127,并且规定计算机只要碰到一个大于127的字节(8位即一个字节),则表示一个汉字的开始。通过这种方式新增了近2万的汉字和符号。像这样的字符集叫做GBK字符集,对应的编码就做GBK编码。
GBK18030后来很多少数民族也使用计算机,于是在GBK的基础上新增了几千个少数民族的字符,对应的字符集叫做GBK18030。
Unicode既然中国可以自己设计字符集和编码,那世界上那么多国家也可以。但是不同国家在进行信息交流的时候,互相的编码是不兼容的,就会出现乱码的情况。比如计算机存储的'10111010111000011'在GBK编码和香港的Big5编码中分别会映射出'好'和'疑'两个完全不同的字符。
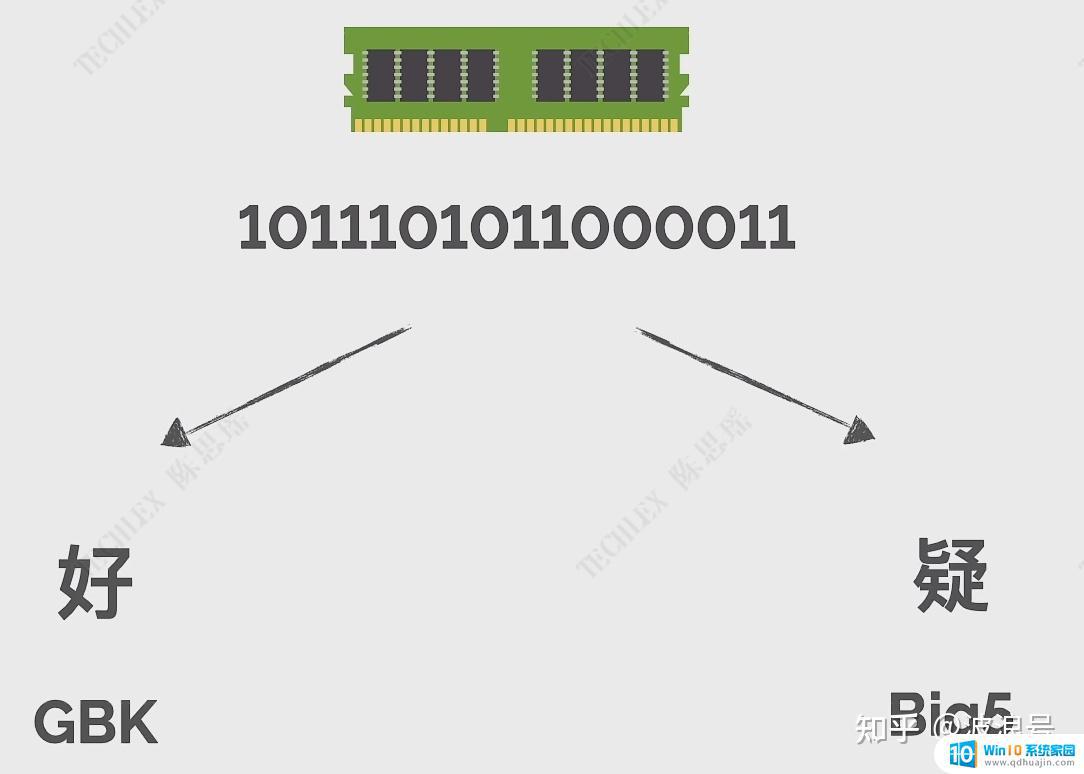
于是一个SO的组织提出了一个支持不同语言的字符集标准Unicode。
UCS-2一开始,Unicode使用的是UCS-2字符集。这个字符集像ASCll一样,将字符按顺序编号,使用2字节(即16比特)长度的二进制信息进行存储,也就是2的16次方也就是65536个字符。
 UCS-4
UCS-4但是后面发现这个65536个字符无法容纳世界上所有字符,于是又出现了UCS-4字符集。它用32位来表示一个字符,也就是2的32次方将近43亿个字符,这基本上就能涵盖世界上所有字符了。
UTF-8虽然解决了容纳所有字符的问题,但这并不适用于所有国家,英文文本ASCll编码本来只需占用1个字节的空间,现在变成了需要使用4个字节,扩大了3倍;中文文本本来只需要占用两个字节的空间,现在变成了需要4个字节,扩大了两倍。所以UCS-4推出后并没有被广泛接受。所幸UTF-8拯救了存储空间的无效使用。
UTF-8在1992年诞生了。UTF-8是针对于Unicode的可变长度编码,不同于编码后长度固定为32比特的UCS-4(即UTF-32),UTF-8将UCS-4的字符集码位划分成4个区间。
码位范围(10进制) 储存在计算机内容
0~127(0x0000 0000~0x0000 007F) 0xxxxxxx
128~2047(0x0000 0080~0x0000 07FF) 110xxxxx 10xxxxxx
2048~65535(0x0000 0800~0x0000 FFFF) 1110xxxx 10xxxxxx 10xxxxxx
65536~1114111(0x0001 0000~0x0010 FFFF) 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
(此处占位符均表示0或1)
1.码位范围在0~127的直接映射为1字节的二进制数
2.对应的编码为2个字节,第一个字节以110开头,第二个字节以10开头
3.以此类推
4.以此类推
那UTF-8到底是怎么编码的呢?
以王字举例:
码位 码位二进制表示 对应的UTF-8格式
王:0x0000 738B 0000 0000 0000 0000 0111 0011 1000 1011 1110xxxx 10xxxxxx 10xxxxxx
将二进制有效字节按顺序插入UTF-8格式中为:11100111 10001110 10001011
最终UTF-8编码为:0xe7 0x8e 0x8b
其实如果是中文的话,可以使用GB2312或GBK。因为它们只需要使用2个字节,而UTF-8需要使用3个字节。
乱码乱码通常是由于编码时使用的字符集和解码时使用的字符集不相同。
锟斤拷通常在UTF-8与中文编码的转换过程中出现。比如UTF-8编码与GBK的转换就会变成这样:
Unicode字符集有一个专门用于提示用户字符无法识别或展示的替换符号:
如果有UTF-8无法识别的字符便会用这个问号替换,在UTF-8中对应的二进制和十六进制如下,如果有两个连着的问号替换符,十六进制则为"EF BF BD EF BF BD"。

这时候再用GBK中文编码解码则会出现 锟斤拷 ,因为GBK编码中,每个汉字用两个字节。
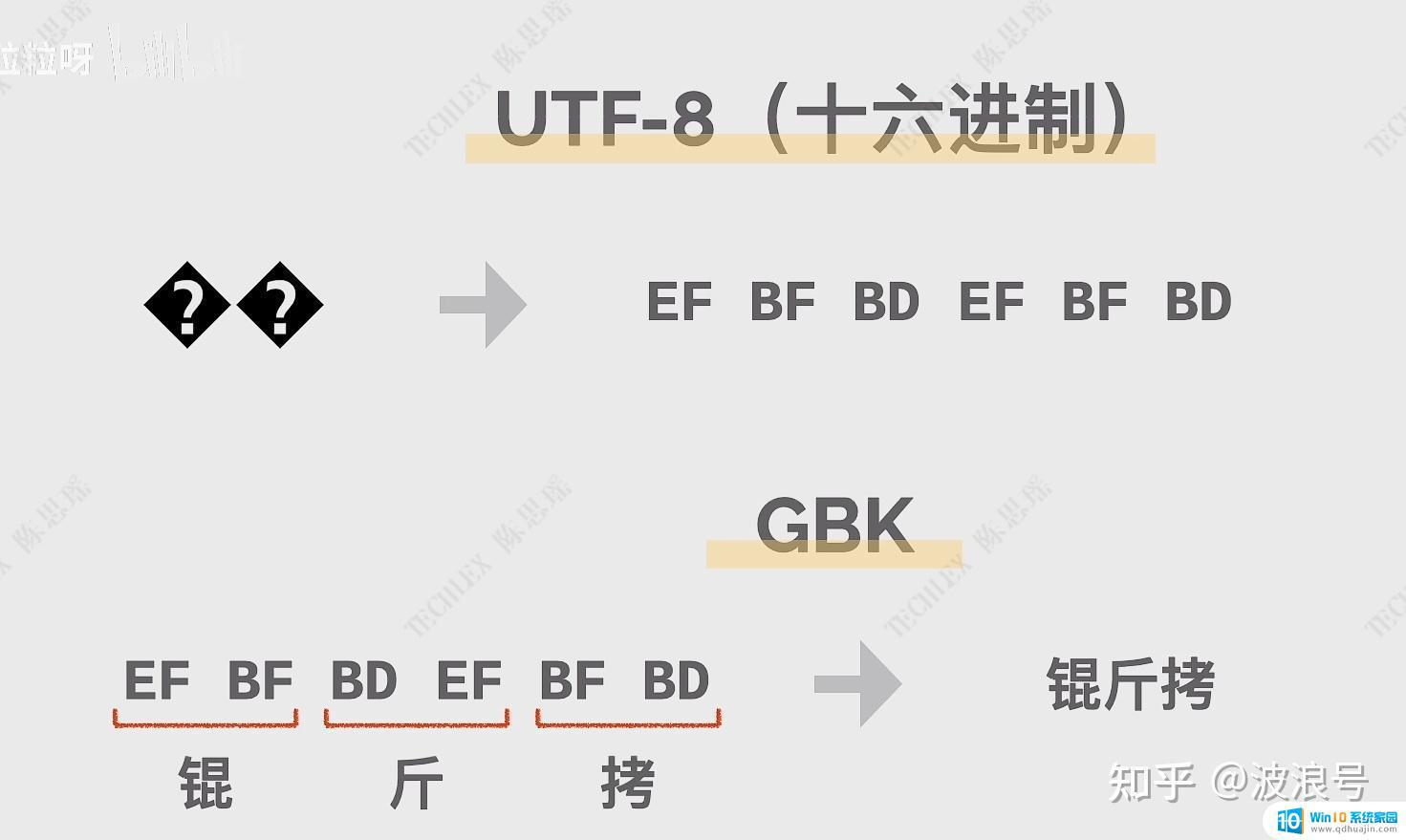
所以锟斤拷 是由UTF-8的连着两个问好替换符转化而来的,乱码之谜终于破解了。

注:部分图片和知识来源B站。
快速有效地解决中文乱码问题对于我们的中文输入和网络使用都有很大的帮助,让我们可以更加高效地进行日常工作和沟通。希望大家能够掌握相应的技巧和方法,避免乱码问题的困扰,享受更好的网络体验。
中文乱码三四五六区 乱码锟斤拷怎么解决相关教程
热门推荐
电脑教程推荐
win10系统推荐
- 1 萝卜家园ghost win10 64位家庭版镜像下载v2023.04
- 2 技术员联盟ghost win10 32位旗舰安装版下载v2023.04
- 3 深度技术ghost win10 64位官方免激活版下载v2023.04
- 4 番茄花园ghost win10 32位稳定安全版本下载v2023.04
- 5 戴尔笔记本ghost win10 64位原版精简版下载v2023.04
- 6 深度极速ghost win10 64位永久激活正式版下载v2023.04
- 7 惠普笔记本ghost win10 64位稳定家庭版下载v2023.04
- 8 电脑公司ghost win10 32位稳定原版下载v2023.04
- 9 番茄花园ghost win10 64位官方正式版下载v2023.04
- 10 风林火山ghost win10 64位免费专业版下载v2023.04