AI圈炸了!微软解封Transformer,序列长度扩展10亿,引发行业震动!
更新时间:2023-07-09 12:46:58作者:qdhuajin
 大数据文摘出品
大数据文摘出品AI圈炸了!微软推出的 LONGNET 成功将Transformer的Token处理能力扩展到了10亿+。
 要知道,之前大家一直夸Transformer的理解能力和短序列生成能力,对长序列一直“有心无力”。微软这一次操作相当于让一个短跑冠军拥有了极速跑马拉松的能力。毕竟,处理长序列的同时,处理短序列任务时依然保持优秀的性能。
要知道,之前大家一直夸Transformer的理解能力和短序列生成能力,对长序列一直“有心无力”。微软这一次操作相当于让一个短跑冠军拥有了极速跑马拉松的能力。毕竟,处理长序列的同时,处理短序列任务时依然保持优秀的性能。LONGNET is a Transformer variant that can scale sequence length to more than 1 billion tokens, with no loss in shorter sequences.
 对此,网友评论:这是一场革命!因为,这项工作为建模长序列提供了新的思路和可能,未来,甚至有望将整个互联网语料视为一个Token。同时,意味着更复杂的 AI 互动成为可能。LONGNET解封序列长度Transformer 模型是许多AI系统的核心架构,工作原理是处理由Tokens组成的信息序列,从而理解或生成文本。注:Token可以是简短的单词或者完整的句子。
对此,网友评论:这是一场革命!因为,这项工作为建模长序列提供了新的思路和可能,未来,甚至有望将整个互联网语料视为一个Token。同时,意味着更复杂的 AI 互动成为可能。LONGNET解封序列长度Transformer 模型是许多AI系统的核心架构,工作原理是处理由Tokens组成的信息序列,从而理解或生成文本。注:Token可以是简短的单词或者完整的句子。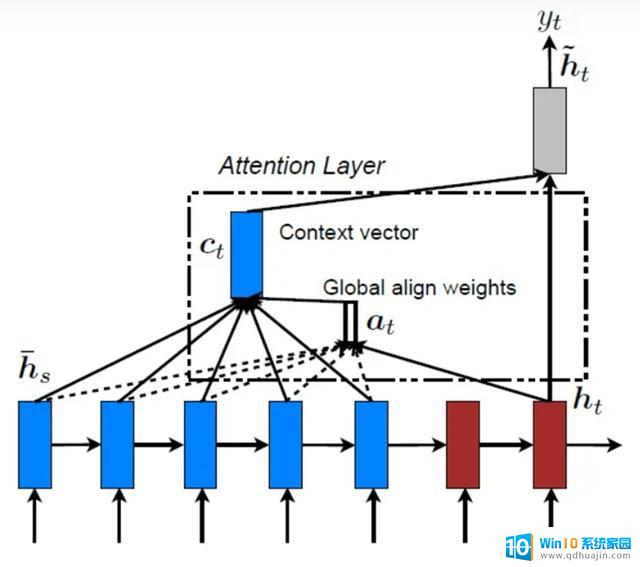 全局注意力机制全局注意力(global attention)是Transformer理解能力的关键所在,它允许一个Token与其他所有Token进行“互动”。序列一旦变得越长,互动次数呈指数级增长,大大增加了计算复杂性。上段内容有点抽象,解释一下:想象一下,你试图与房间里的每一个人分别进行对话。如果只有几个人,这是可以应对的。但随着人数的增加,很快就变得难以承受。ChatGPT就是 OpenAI 基于Transformer开发的,大家在使用它进行上下文对话的时候,会发现它会经常“忘”了你之前给他说过的话。以后,有了LONGNET 就解锁了ChatGPT无限对话能力,它会记起你最开始的提问。LONGNET的核心:扩张注意力的力量
全局注意力机制全局注意力(global attention)是Transformer理解能力的关键所在,它允许一个Token与其他所有Token进行“互动”。序列一旦变得越长,互动次数呈指数级增长,大大增加了计算复杂性。上段内容有点抽象,解释一下:想象一下,你试图与房间里的每一个人分别进行对话。如果只有几个人,这是可以应对的。但随着人数的增加,很快就变得难以承受。ChatGPT就是 OpenAI 基于Transformer开发的,大家在使用它进行上下文对话的时候,会发现它会经常“忘”了你之前给他说过的话。以后,有了LONGNET 就解锁了ChatGPT无限对话能力,它会记起你最开始的提问。LONGNET的核心:扩张注意力的力量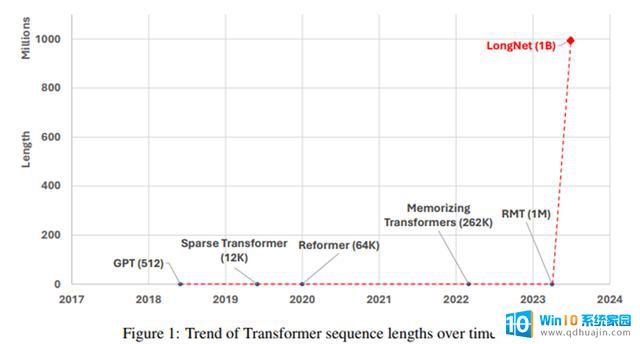 在LONGNET这项工作中,微软的研究员将一种称为“扩张注意力”(dilated attention)的新颖概念引入到Transformer 模型中,从根本上改变了模型处理序列的方式。扩张注意力的妙用在于,距离增大时能够关注更多的Token,而无需让每个序列与其他所有序列互动。就像,在人群中既能关注到附近的人,也能关注到远离的人,但不需要与每个人单独交谈。
在LONGNET这项工作中,微软的研究员将一种称为“扩张注意力”(dilated attention)的新颖概念引入到Transformer 模型中,从根本上改变了模型处理序列的方式。扩张注意力的妙用在于,距离增大时能够关注更多的Token,而无需让每个序列与其他所有序列互动。就像,在人群中既能关注到附近的人,也能关注到远离的人,但不需要与每个人单独交谈。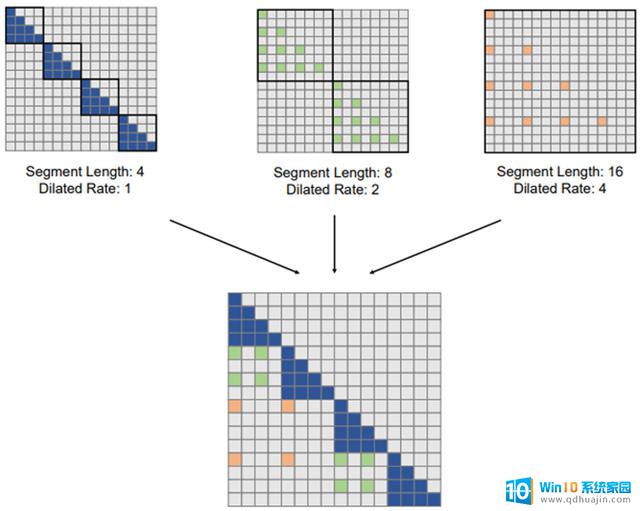

图注:不同方法之间计算复杂性的比较。N 是序列长度,d 是隐藏层的维度。
此外,研究人员将 LONGNET 与传统的 Transformer 和稀疏 Transformer 进行了对比。为了进行比较,他们将这些模型的序列长度从 2,000 个标记(2K)扩展到 32,000 个标记(32K)。为了确保比较的公平性,他们调整了各模型的参数。尽管在计算上有一定限制,但实验结果仍然非常出色。同时,增加模型参数从1.2亿到27亿,随着LongNet的计算量增加,在测试集上的PPL也随之降低。这体现出,LongNet同样满足scaling law。训练更大的语言模型可能能取得更好的表现。LONGNET并非没有局限,例如虽然扩张注意力机制将计算复杂性降低到低于标准 Transformer 模型的水平,但处理超过 10 亿个标记的序列仍然需要大量资源。此外,虽然有强大的性能,但可能仍需要进行更多的测试和验证。微软也提出了关于LONGNET的未来研究方向:如何进一步优化扩张注意力机制?是否有其他序列处理技术可以与扩张注意力相辅相成?如何将LONGNET 有效地整合到现有的 AI 系统(如 ChatGPT)中?
论文地址:
https://arxiv.org/abs/2307.02486
参考来源:
https://thetechpencil.com/revolutionizing-ai-with-longnet-microsofts-breakthrough-in-handling-billion-token-sequences-59b05ef7d6e8
https://mp.weixin.qq.com/s/Qns4Oi8-YHWb7WP3_gGZUA

AI圈炸了!微软解封Transformer,序列长度扩展10亿,引发行业震动!相关教程
热门推荐
微软资讯推荐
- 1 如何查看电脑显卡型号及性能信息的方法,轻松掌握显卡信息
- 2 如何打开NVIDIA显卡控制面板的详细步骤解析,一步步教你轻松设置显卡参数
- 3 微软推荐迁移至Win11新版Outlook,邮件和日历应用今年终止支持
- 4 Windows可以直接运行安卓手机App了,轻松在电脑上使用安卓应用
- 5 国产游戏显卡 唯一DX12!摩尔线程要上市了,性能超越国外同类产品
- 6 三季度手机处理器市场数据:苹果收入最高,联发科总量第一
- 7 微软Win10 22H2/21H2推送11月累积更新:修复打印机问题最新
- 8 索泰显卡的性能与性价比全面评测:索泰显卡性价比如何?
- 9 数亿台电脑面临“退休”危机!Windows 10用户抓紧升级!
- 10 微软确认Win10/Win11锁屏未来支持编辑、移除MSN小部件
win10系统推荐
- 1 萝卜家园ghost win10 64位家庭版镜像下载v2023.04
- 2 技术员联盟ghost win10 32位旗舰安装版下载v2023.04
- 3 深度技术ghost win10 64位官方免激活版下载v2023.04
- 4 番茄花园ghost win10 32位稳定安全版本下载v2023.04
- 5 戴尔笔记本ghost win10 64位原版精简版下载v2023.04
- 6 深度极速ghost win10 64位永久激活正式版下载v2023.04
- 7 惠普笔记本ghost win10 64位稳定家庭版下载v2023.04
- 8 电脑公司ghost win10 32位稳定原版下载v2023.04
- 9 番茄花园ghost win10 64位官方正式版下载v2023.04
- 10 风林火山ghost win10 64位免费专业版下载v2023.04
系统教程推荐
- 1 win11如何在桌面加时钟 Win11预览版新小组件定时器和倒数日如何操作
- 2 win11调整到顶部 Win11如何移动任务栏到顶部
- 3 win11如何调整电脑屏幕显示大小 电脑屏幕分辨率怎么调整
- 4 ps4手柄能连电脑 完美吗 win11 ps4手柄连接电脑教程
- 5 怎样设置win11不自动更新 怎样关闭Win11系统自动更新
- 6 win11无法安装软件的教程 Win11升级后无法安装软件怎么办
- 7 win10鼠标移动会卡顿 win10系统鼠标卡顿怎么解决
- 8 win11打印机 怎么扫描pdf 怎么使用扫描仪扫描PDF文件
- 9 win11系统恢复分区怎么删除 win11磁盘恢复分区删除步骤
- 10 win11打开rar文件闪退怎么解决 Win10打开rar文件闪退解决方法