英特尔至强6性能核处理器:核心破百,性能翻倍,数据中心算力升级速度快
特别是在“四年五个制程节点”战略的引领之下,英特尔近年来产品创新的速度实际上是相当快的,于是在6月份发布了至强6能效核处理器之后,英特尔也于本月正式发布了英特尔有史以来性能最强大的至强处理器:英特尔至强6性能核处理器(Granite Rapids)。
至于为什么要把至强6拆分为两个产品线,则主要源于数据中心客户的不同需求:一方面,AI的火热需要算力平台具备更加强大的AI算力;而另一方面,对性能要求不高,但对并发量要求极高的微服务应用则对能耗比有着更高需求。
因此,至强6性能核处理器与至强6能效核处理器之间的关系更像是战略互补,实现了对数据中心的“对症下药”:前者具备更高的性能、内核密度、内存和I/O创新,同时也有更高的能耗,针对计算密集型和AI工作负载进行了优化,例如设计、大数据、AI推理以及游戏场景;而后者具备更高的能效,针对高密度和横向扩展工作负载进行了优化,如微服务、云原生负载或者简单的数据库处理。但二者共享一个底层平台,这不仅缩短了英特尔自身的开发和设计周期,也减少了最终客户的部署难度。
这里也要明确一下,目前的AI应用实际上可以分为两大类。一类是基于GPU的重负载训练应用,另一类则是对延迟和能效更加敏感的轻应用,对这类应用而言,通过使用CPU混合精度即可实现的推理吞吐量反而能带来更高的灵活性和更具优势的TCO,这也是近几年的至强处理器主攻的方向,英特尔数据中心与人工智能集团副总裁兼中国区总经理陈葆立表示,目前已经有很多客户使用至强CPU测试了Llama2和Llama3的推理性能,并且表现出色,从英特尔的角度出发,希望能通过至强6处理器为企业提供底层的算力基础设施,帮助他们在部署私有模型或私有知识库,并利用大模型进行AI创新。
性能方面,英特尔至强6性能核处理器也是不负“史上最强至强”之名。与第五代英特尔至强可扩展处理器相比,至强6处理器拥有多达2倍的每路核心数,平均单核性能提升高达1.2倍,平均每瓦性能提升高达1.6倍,同等性能水平下平均节省30%的TCO,同时在数据中心常见的通用计算、数据和Web服务、科学计算和AI等工作负载中,至强6性能核处理器在性能和每瓦性能上,相比上一代处理器也有显著提高。
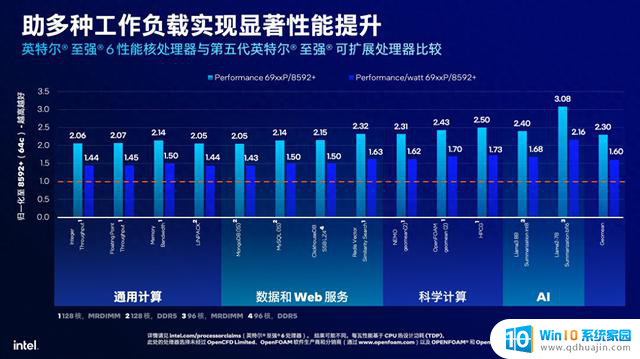
之所以能实现如此大的性能提升,则与至强6优秀的架构设计脱不开关系:至强6在芯片设计层面采用了按照功能块进行划分的方式:包括包含X86内核、内存控制器和缓存单元的计算die和包括UPI、PCIe控制器、DSA/IAA/QAT/DLB等加速器的I/O die,两者通过EMIB(嵌入式多芯片互连桥接)技术相连接。通过改变计算单元的数量和I/O die的规格,即可衍生出不同的产品线,从而满足云边端对性能和能耗的多样化需求。以性能最为强大的至强6900P系列处理器为例,共包含3个计算die,核心数量最多为128个,还支持最多6条UPI 2.0链路(速率高达24GT/s),96条PCIe 5.0或64条CXL 2.0通道,并拥有高达504MB的L3缓存。

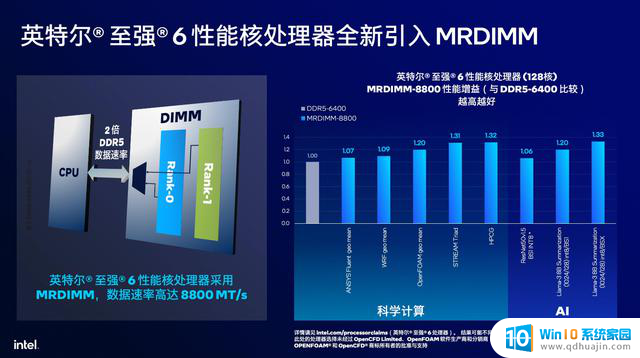
值得一提的是,时下最受瞩目的HPC和AI领域对于内存带宽、速度和吞吐都有着不小的需求。单独增加核心数量很容易造成内存性能的瓶颈,为了解决这一问题,至强6900系列处理器拥有12通道的内存,支持6900MT/s的DDR5内存或8800MT/s的MRDIMM内存,从而让每个核心拥有了更加充裕的内存带宽,更加有利于核心性能的释放,从而在科学计算、生成式AI、深度学习、机器学习、推理训练等场景中获得更好的表现。
在AI加速方面,从第四代至强可扩展处理器上开始引入的AMX加速器在此前支持BF16和INT8数据类型的基础上,引入了FP16的数据精度,这也为AI推理和训练提供了更多精度上的选择。新华三集团计算存储产品线副总裁刘宏程在接受采访时表示,“至强6通过AMX技术,在推理性能上实现了显著提升,包括INT8、BF16、FP16等多种精度上的优化,使得客户无需额外投资即可享受AI推理带来的便利,这无疑将推动市场向更加融合的方向发展,即所有服务器都将具备AI强化的功能。”
异构计算方面,至强6处理器作为英特尔首代支持CXL 2.0规范的处理器,不但极大地提高了内存利用率,也为未来内存扩展和内存池化奠定了基础。在实际的应用场景中,客户可以通过CXLNUMA节点模式、异构交织模式(Hetero Interleaved)和扁平内存模式(Flat Memory)三种模式实现内存的扩展。

围绕至强6性能核处理器的这一特性,超聚变也联合英特尔推出了全球首个支持CXL 2.0+的内存池解决方案,在全面支持CXL 2.0标准协议的同时,可以通过软件实现基于CXL 3.1的数据共享能力,通过多样的使用模式,可以充分满足不同的应用场景,如内存扩展、池化弹性分配、数据传输和数据共享等,从而为最终客户带来更高的灵活性和性价比。
“大模型的推理和训练带来了内存需求的旺盛增长,并造成了内存价格的持续走高,基于市场本身的需求出发,超聚变会和英特尔进行持续的合作,让CXL技术更好地落地,引领ICT基础设施迈向新的发展阶段。”超聚变服务器产品总经理朱勇总结道。
热功耗方面,性能最强的至强6900P系列处理器TDP达到了500W,也比第五代至强可扩展处理器最高的350W高出了一截,但核心密度的提升反而弥补了单个CPU功耗增加的问题。
不过对数据中心而言,随着对算力需求的日益增长,也需要考虑节能降碳的问题,特别是在国家层面的“双碳目标”确立之后,建设绿色数据中心也成为了重要的社会责任,而液冷技术则有望成为破局的关键。“在未来,随着CPU功耗和性能的提升,液冷势必会越来越普及,而且不仅仅是针对CPU,甚至包括内存、硬盘、电源等部件,技术上的难点实际上并不多,关键在于产业化和标准化。”联想基础设施业务群服务器产品部总经理周韬总结道。
而这也是英特尔启动中国数据中心液冷创新加速计划的重要原因之一。具体来说,针对浸没式液冷,英特尔在今年早些时候联合绿色云图推出的基于G-flow技术的解决方案可以让数据中心实现更低的PUE和更佳的TCO;而针对冷板式液冷,英特尔则很早就与多个OEM、ODM厂商共同推出了参考设计方案,以供生态合作伙伴参考。

以联想推出的ThinkSystem SC750 V4液冷服务器为例,通过联想自研的第六代温水水冷技术,可以实现服务器100%的全覆盖浸没式液冷,从而有效降低整个数据中心的PUE,实现零噪音数据中心。
秉承“冷静计算”战略的宁畅也围绕液冷技术与英特尔进行了很多合作,宁畅副总裁兼首席技术官赵雷表示。为了能让基于至强6性能核处理器的宁畅BR60 T62实现高效的冷板散热,双方进行了非常多的深度合作,首先是在无风扇的情况下实现冷板全覆盖,尤其是涉及到SSD、网卡等部件的时候,虽然这类部件尺寸结构通用,但散热器设计却没有统一的标准;其次,为了进一步降低PUE,整机柜内还设置了两级流量调节泵,以最大化利用冷源流量,使整机柜实现最低1.05的极限PUE。
当然,无论性能如何强大,至强6毕竟只是算力的载体,要想进一步释放算力价值,让AI应用更好的落地,除了硬件方面的支持,软件方面也需要更好地创新,为此,英特尔也联合行业内的领先企业共同创建了开放的AI开发和部署平台:企业AI开放平台(OPEA),以帮助企业加速生成式AI系统的可靠与高效部署,助力终端用户快速应用。
“对英特尔来说,我们的最终目标是通过深层次的合作和不断完善的生态系统,解决客户所面临的问题,并推动AI技术在企业中的应用和发展。”英特尔市场营销集团副总裁、中国区云与行业解决方案和数据中心销售部总经理梁雅莉在最后表示。
(9041377)
英特尔至强6性能核处理器:核心破百,性能翻倍,数据中心算力升级速度快相关教程
热门推荐
微软资讯推荐
- 1 如何查看电脑显卡型号及性能信息的方法,轻松掌握显卡信息
- 2 如何打开NVIDIA显卡控制面板的详细步骤解析,一步步教你轻松设置显卡参数
- 3 微软推荐迁移至Win11新版Outlook,邮件和日历应用今年终止支持
- 4 Windows可以直接运行安卓手机App了,轻松在电脑上使用安卓应用
- 5 国产游戏显卡 唯一DX12!摩尔线程要上市了,性能超越国外同类产品
- 6 三季度手机处理器市场数据:苹果收入最高,联发科总量第一
- 7 微软Win10 22H2/21H2推送11月累积更新:修复打印机问题最新
- 8 索泰显卡的性能与性价比全面评测:索泰显卡性价比如何?
- 9 数亿台电脑面临“退休”危机!Windows 10用户抓紧升级!
- 10 微软确认Win10/Win11锁屏未来支持编辑、移除MSN小部件
win10系统推荐
- 1 萝卜家园ghost win10 64位家庭版镜像下载v2023.04
- 2 技术员联盟ghost win10 32位旗舰安装版下载v2023.04
- 3 深度技术ghost win10 64位官方免激活版下载v2023.04
- 4 番茄花园ghost win10 32位稳定安全版本下载v2023.04
- 5 戴尔笔记本ghost win10 64位原版精简版下载v2023.04
- 6 深度极速ghost win10 64位永久激活正式版下载v2023.04
- 7 惠普笔记本ghost win10 64位稳定家庭版下载v2023.04
- 8 电脑公司ghost win10 32位稳定原版下载v2023.04
- 9 番茄花园ghost win10 64位官方正式版下载v2023.04
- 10 风林火山ghost win10 64位免费专业版下载v2023.04
系统教程推荐
- 1 给电脑软件换图标 电脑软件图标修改方法
- 2 台式电脑前侧耳机没声音 Win11电脑插耳机为什么没有声音
- 3 怎么把桌面文件夹存到d盘 Win10系统如何将桌面文件保存到D盘
- 4 win11桌面图片如何设置 如何在Windows11上设置个性化壁纸
- 5 win11开机自启动便筏 win11开机自启动软件设置方法
- 6 怎样把搜狗输入法放到任务栏 怎么把搜狗输入法固定到任务栏
- 7 键盘锁死无法打字 键盘怎么办锁住了
- 8 电脑上不显示耳机选项 win10电脑插上耳机没有声音
- 9 笔记本电脑刚开机就自动关机是怎么回事 笔记本电脑开机后几秒钟自动关机
- 10 台式电脑里面有蓝牙吗 电脑有没有蓝牙怎么查看